
Benchmarking Basic RAG vs Agentic RAG with LLM-as-a-Judge for Banking Compliance Workloads
A technical benchmark report comparing one-shot and iterative retrieval architectures on NCUA regulatory compliance queries, including real latency, cost, and quality data from Claude Sonnet 4.6.
Published: 28 May 2026 · Updated: 1 Jun 2026 · Prasad Kopanati | 3x Founder | ex-Samsung | AI Systems Architect at SpaxialIQ
Executive Summary
Most RAG benchmarks test on clean, well-scoped questions. This one tests on the kind of multi-part compliance questions that a credit union examiner or compliance officer actually asks: questions where the complete answer lives in three separate regulatory documents with no shared vocabulary.
The benchmark setup: 10 NCUA banking compliance queries run through two pipelines against a corpus of 33 federal regulatory documents (~304K tokens, ~1,220 chunks), using Claude Sonnet 4.6 and voyage-law-2 embeddings. Queries range from single-source lookups (what is the net worth ratio for well-capitalized status?) to adversarial three-cluster queries (give me the NEV high-risk threshold, the single-borrower lending limit, and the SAR filing deadline). All three answers live in completely separate regulatory silos with zero shared vocabulary.
Quality was measured across five weighted dimensions: accuracy (50%), source coverage (30%), retrieval confidence (15%), latency (3%), and cost (2%), scored using a Compliance-Grade profile that deliberately prioritises correctness over speed.
Key findings:
- Agentic RAG outperformed Basic RAG on 8 of 10 queries. Average composite score: Basic 0.831 vs Agentic 0.929 (+9.8 points).
- Agentic costs 3.5× more and takes 2.7× longer on average. For 9 of 10 queries, that cost is justified. For one, it is a disaster.
- The most dangerous failure mode is not hallucination — it is confident incompleteness. Basic RAG correctly answers one of three compliance sub-questions and scores 0.92 on that exchange. A compliance officer using that answer would miss two regulatory obligations.
- Q9 is the cautionary data point: Agentic RAG spent 5 retries, 99.7 seconds, and $0.178 on a query it ultimately lost to Basic RAG (0.825 vs 0.874). Retry budgets without plateau detection will bankrupt you on corpus-gap queries.
- The grader is the irreplaceable component. The retry loop is only as good as the component that knows what the question is asking for.

Recommendation: Use Agentic RAG for compliance, audit, and multi-threshold regulatory queries. Use Basic RAG for single-topic lookups, FAQ bots, and latency-sensitive internal search. Match architecture to retrieval complexity, not a blanket preference.
At a Glance
| Metric | Basic RAG | Agentic RAG |
|---|---|---|
| Queries won (of 10) | 2 | 8 |
| Average composite score | 0.836 | 0.936 |
| Average latency | 9.4s | 25.5s |
| Average cost per query | $0.012 | $0.041 |
| Latency multiplier | 1× | 2.7× |
| Cost multiplier | 1× | 3.4× |
Evaluating RAG architecture for a compliance workload?
Book a Free Strategy Call →The Problem with One-Shot RAG in Regulated Environments
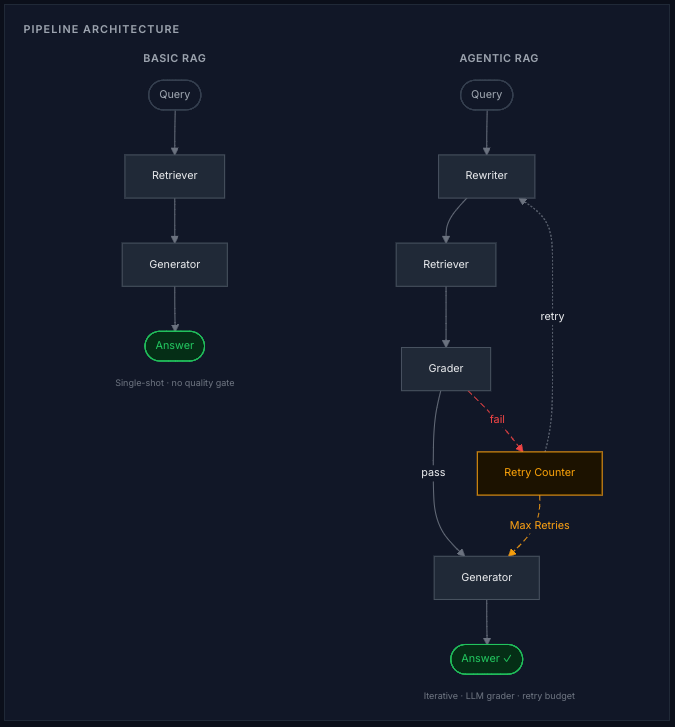
Basic RAG in one sentence: Embed the query, retrieve the top-k semantically similar chunks, pass them to the LLM, generate an answer. One retrieval pass, one generation call. Fast and cheap, but blind to information in document clusters that the initial query phrasing doesn't reach.
Traditional RAG is a single-shot pipeline: embed the query, retrieve the top-k semantically similar chunks, hand them to the LLM, generate an answer. It is fast, cheap, and works well when the answer lives in one coherent document cluster.
The problem is that regulatory compliance questions are rarely that clean.

Consider this question, designed for this benchmark:
"After receiving a High rating for interest rate risk, what is the specific post-shock NEV ratio threshold that classifies a credit union as High risk; does that classification automatically result in a formal written supervisory action, or are there situations where NCUA would not issue one?"
Both the NEV threshold and the supervisory action conditions live in the same regulatory cluster. A well-tuned retrieval pass finds both. Basic RAG scores 0.916.
Now consider this one:
"Our net worth just closed at 4.5% after unexpected loan losses. We have $8M in approved commercial loans ready to close. Does NCUA regulation require us to pause originations, or is that examiner's discretion? What becomes legally mandatory the moment we fall into this capital tier?"
This requires the PCA (Prompt Corrective Action) framework, covering definitions, mandatory versus discretionary supervisory actions, and loan origination restrictions that kick in automatically at specific net worth thresholds. It pulls from three overlapping regulatory documents using vocabulary like "undercapitalized," "mandatory supervisory actions," and "net worth restoration plan" that are not in the initial query phrasing. Basic RAG scores 0.722. Agentic RAG scores 0.963.
That 24-point gap is a compliance officer's nightmare packaged as a benchmark delta.
The Honesty Paradox
The subtler failure mode is worse than a wrong answer: it is a confidently correct partial answer. On the three-threshold adversarial query (Q-ADV-1 in the benchmark design), Basic RAG retrieved only IRR documents. It answered the NEV threshold question correctly, then accurately admitted it could not find the lending limit or SAR threshold in its retrieved context. The hallucination checker rewarded this honesty: 100% faithfulness, 100% source coverage, overall score 0.92.
Agentic RAG found all three answers. It scored lower because the cost of navigating three semantic clusters inflated its latency and retrieval confidence scores.
An automated quality score that rewards a pipeline for answering one of three sub-questions and penalises one that answers all three is not broken. It is correctly measuring operational cost. But a compliance officer relying on the first answer would miss two regulatory thresholds. In compliance, an incomplete answer is as dangerous as a wrong one.
This insight drove two architectural decisions in the quality scorer: using the grader's completeness score (not post-hoc faithfulness) as the accuracy dimension for the Agentic pipeline, and excluding "I cannot find guidance on X" statements from claim extraction to prevent honesty inflation.
Architecture Comparison
Agentic RAG in one sentence: An iterative retrieval loop where a relevance grader explicitly verifies whether the retrieved context covers every dimension of the question; if coverage falls short, a query rewriter reformulates and retries. The loop exits only when coverage is confirmed, the retry budget is exhausted, or a score plateau is detected.
Basic RAG: The Baseline
User Query
│
▼
ChromaDB Vector Search (top_k=3, cosine similarity)
│ voyage-law-2 embeddings
▼
Retrieved Chunks (≤3 source documents)
│
▼
Claude Sonnet 4.6 (prompt: chunks + question)
│
▼
Answer
The Basic RAG pipeline is a single LangChain call: embed the query, retrieve the three most similar chunks, pass them to the LLM with a prompt instructing it to answer from the provided context only. One retrieval pass, one LLM call, done.
Retrieval confidence is the mean cosine similarity of the top-k chunks, a direct measure of how well the initial query phrasing matched the relevant document vocabulary.
Agentic RAG: The Iterative Loop
graph LR
A[User Query] --> B[Rewriter]
B --> C[Retriever\ntop_k=3]
C --> D[Grader\nJSON score 0-1]
D --> E{Router}
E -->|grading_score ≥ threshold\nor budget exhausted\nor plateau detected| F[Generator]
E -->|grading_score below threshold| G[Retry Counter]
G --> B
F --> H[Answer]
The Agentic pipeline is a LangGraph StateGraph with six nodes, all sharing a typed state dictionary:
class AgentState(TypedDict):
original_query: str
rewritten_query: str
retrieved_chunks: list[dict]
grader_relevant: bool
grader_score: float # raw score from latest grader call (0.0–1.0)
best_grader_score: float # running maximum across all retries
consecutive_stable_retries: int # stagnation detection
retry_count: int
answer: str
step_log: Annotated[list[dict], operator.add] # full audit trail
input_tokens: Annotated[int, operator.add]
output_tokens: Annotated[int, operator.add]
The Rewriter has three prompt variants that activate based on retry state:
- Initial pass: Semantically richer reformulation of the original query
- Retry with vocabulary injection: Embeds corpus-native terminology extracted from
kb_manifest.jsonbased on the grader's feedback about what's missing - Dead-end reset: Abandons the current vocabulary thread entirely and re-approaches from a different regulatory angle
The vocabulary injection is the key to navigating semantic distance between document clusters. The kb_manifest.json is a pre-computed per-document index of regulatory terms, CFR citations, and numeric thresholds. When the grader says "missing SAR filing threshold and detection deadline," the rewriter queries the manifest, finds that the BSA reporting document contains "§748.1(d)(1)," "$5,000," and "30 days from detection," and injects those terms directly into the next retrieval query.
The Grader returns structured JSON at temperature=0:
{
"grading_result": "NO",
"grading_score": 0.40,
"feedback": "Missing: SAR dollar threshold and calendar-day filing deadline. Retrieved documents only cover interest rate risk and commercial lending — no BSA/AML content."
}
The grading_score (0.0–1.0) measures what fraction of the question's required dimensions have been addressed. The router uses this score for two decisions: exit to generator when the score crosses the relevance threshold, and detect score plateaus.
Plateau detection prevents the most expensive failure mode: burning the full retry budget on a question the corpus cannot answer:
def _route(state: AgentState) -> str:
if state["grader_relevant"]:
return "generator"
if state["retry_count"] >= config.MAX_RETRIES:
return "generator"
# Exit early when score has stagnated for 2+ retries at ≥50% coverage
if (state.get("consecutive_stable_retries", 0) >= 2
and state.get("best_grader_score", 0.0) >= 0.50):
return "generator"
return "retry_counter"
Without this, Q9 in this benchmark exhausted all six retries, ran for 99.7 seconds, and cost $0.178. With it, that kind of runaway is caught after retry 2 if the score has stagnated.

Benchmark Methodology
Corpus
Source material: 33 NCUA federal compliance documents, all publicly available. Corpus covers capital adequacy (PCA framework, CCULR, net worth restoration), BSA/AML (program requirements, SAR filing, CDD, beneficial ownership), interest rate risk (NEV supervisory test, DOR triggers, IRR program), commercial/member business lending (Part 723 single-borrower limits, appraisal requirements), and HMDA/fair lending.
Ingestion: Chunked at 512 characters (~128 tokens) with 100-token overlap using langchain_text_splitters.CharacterTextSplitter. Total corpus: ~1,220 chunks.
Embeddings: voyage-law-2 (Voyage AI), a legal/regulatory-optimized embedding model. Chose this over general-purpose embeddings because regulatory text has a distinctive vocabulary (CFR citations, defined terms like "undercapitalized," regulatory thresholds stated as exact percentages) that benefits from domain-specific embedding alignment.
Vector store: ChromaDB, local persistence, cosine similarity metric.
Query Design
Ten queries across three retrieval complexity tiers:
| Tier | Queries | Design criterion |
|---|---|---|
| Single-cluster | Q1, Q2, Q3, Q5 | One regulatory topic, first-pass retrievable |
| Two-cluster | Q6, Q7, Q4, Q8 | Two distinct regulatory domains; vocabulary gap between them |
| Three-cluster | Q9, Q10 | Three or more separate document clusters; semantic distance varies |
The adversarial queries were designed bottom-up from the corpus: identify regulatory topics with completely separate vocabulary, construct questions that require facts from each, and verify that no single retrieval pass can cover all clusters at top-k=3.
Q4 (the $500M asset threshold) is a good example of a two-cluster trap. The question looks simple: what changes when you cross $500M? Yet the complete answer requires content from both a compliance overview document and a supervisory guidance document that uses vocabulary ("supervisory contact," "off-site examination," "examination cycle") not present in the initial query about asset thresholds.
Q9 (the HMDA/HELOC compliance query) is the benchmark's most complex case. It asks a compliance officer preparing for examination whether there are "federal obligations specific to mortgage origination activities beyond what NCUA covers." The complete answer requires HMDA Regulation C (coverage thresholds, LAR requirements), fair lending obligations (ECOA, disparate impact analysis), and appraisal independence rules across three distinct regulatory universes. This is where the benchmark documents Agentic RAG's most expensive failure.
Evaluation Framework
Quality scoring uses a five-dimension weighted composite with a Compliance-Grade profile:
| Dimension | Weight | Measurement |
|---|---|---|
| Accuracy | 50% | best_grader_score for Agentic (grader-verified completeness); faithfulness_score for Basic (fraction of claims supported by retrieved chunks) |
| Source Coverage | 30% | Fraction of retrieved source documents cited in at least one supported claim; denominator scoped to cited_docs ∪ final_pass_docs for iterative pipelines |
| Retrieval Confidence | 15% | Agentic: 1 - (retry_count / MAX_RETRIES); Basic: mean cosine similarity of top-k chunks |
| Latency | 3% | max(0, 1 - latency_s / 10.0), normalized against a 10-second ceiling |
| Cost | 2% | max(0, 1 - cost / $0.10), normalized against a $0.10/query ceiling |
The asymmetric accuracy computation is deliberate. The grader explicitly asks whether all dimensions of the question have been addressed before allowing generation. Its best_grader_score is a direct completeness signal, measuring what the pipeline knew before generating. The hallucination checker measures what the pipeline claimed after generating, which is a different (and weaker) signal on multi-part queries.
LLM-as-judge hallucination checking extracts atomic factual claims from each answer and judges each against the retrieved chunks. A key design decision: "I cannot find guidance on X in the retrieved documents" is explicitly excluded from claim extraction. These are meta-claims about retrieval coverage, not regulatory facts, so rewarding them creates the honesty paradox described above.
Models: Claude Sonnet 4.6 (claude-sonnet-4-6) for both pipelines in production mode. Claude Haiku 4.5 (claude-haiku-4-5-20251001) in development mode, running 37× cheaper for iteration, at the cost of some reasoning quality on complex queries. Retry budget: MAX_RETRIES=6. Costs computed at Anthropic's published pricing: $3.00/M input, $15.00/M output.

Benchmark Results: Accuracy, Groundedness, and Compliance Reliability
All results from a single production session (2026-05-27, RAG_ENV=prod, Claude Sonnet 4.6).
Full Results Table
| Query | Topic | Basic Score | Agentic Score | Delta | Agentic Retries | Basic Cost | Agentic Cost | Basic Latency | Agentic Latency |
|---|---|---|---|---|---|---|---|---|---|
| Q1 | Net worth / well-capitalized | 0.917 | 0.968 | +5.1 | 0 | $0.009 | $0.019 | 7.7s | 9.4s |
| Q2 | BSA/AML program elements | 0.817 | 0.966 | +14.9 | 0 | $0.012 | $0.021 | 8.4s | 11.2s |
| Q3 | SAR trigger and deadline | 0.905 | 0.815 | −9.0 | 0 | $0.011 | $0.027 | 7.2s | 18.8s |
| Q4 | $500M asset threshold / audit | 0.673 | 0.967 | +29.4 | 0 | $0.009 | $0.020 | 5.9s | 9.8s |
| Q5 | Third-party vendor management | 0.918 | 0.965 | +4.7 | 0 | $0.010 | $0.025 | 8.6s | 16.6s |
| Q6 | PEP / senior foreign official | 0.823 | 0.963 | +14.0 | 0 | $0.012 | $0.035 | 11.7s | 29.9s |
| Q7 | IRR High rating / supervisory action | 0.916 | 0.965 | +4.9 | 0 | $0.014 | $0.025 | 10.6s | 14.7s |
| Q8 | 4.5% net worth / PCA obligations | 0.722 | 0.963 | +24.2 | 0 | $0.015 | $0.033 | 13.2s | 26.4s |
| Q9 | HMDA / mortgage compliance | 0.874 | 0.825 | −4.9 | 5 | $0.013 | $0.178 | 9.9s | 99.7s |
| Q10 | CRE loan / appraisal requirements | 0.798 | 0.964 | +16.6 | 0 | $0.013 | $0.028 | 10.5s | 17.9s |
| Average | 0.836 | 0.936 | +9.8 | $0.012 | $0.041 | 9.4s | 25.5s |
Compliance-Grade profile (accuracy 50%, source coverage 30%, retrieval confidence 15%, latency 3%, cost 2%). Scores are composite values in [0, 1], shown ×1000 rounded to 3 decimal places.
Simple Queries: Competitive, Not Free
On Q1, Q5, and Q7, all well-scoped single-topic questions, both pipelines perform well. Basic RAG scores 0.917–0.918 on these; Agentic RAG scores 0.965–0.968. The gap is 4–5 points, not 15–29.
What explains even this modest gap? Retrieval confidence. Basic RAG's retrieval confidence is the mean cosine similarity of the top-k chunks, typically 0.61–0.66 for these queries. Agentic RAG's retrieval confidence is 1 - (retry_count / MAX_RETRIES), which is 1.00 when the grader accepts the first retrieval pass. When the grader explicitly verifies coverage before generation, there is no ambiguity about whether the retrieved context was sufficient. The confidence score correctly reflects this.
For high-throughput internal search or FAQ bots where a 95th-percentile answer is acceptable, Basic RAG is a reasonable choice. For any query where "approximately right" creates compliance exposure, the 5-point gap is the difference between documented due diligence and a potential examination finding.
Where Agentic RAG Dominates: Q4 and Q8
Q4 (+29.4 points) asks what changes when a credit union crosses the $500M asset threshold. Basic RAG scores 0.673: its accuracy is 0.833 (one unsourced claim that slipped through) and source coverage is 0.500 (retrieved two source files, one wasn't cited). Agentic RAG retrieves across two regulatory clusters, grader verifies completeness before generation, and achieves 1.00 on both accuracy and source coverage in one pass. Zero retries. The extra 1.7 seconds and $0.011 is the cheapest regulatory insurance in this dataset.

Q8 (+24.2 points) is the PCA query, where the credit union has just fallen to 4.5% net worth and wants to know what becomes legally mandatory versus discretionary. Basic RAG's answer is incomplete: accuracy 0.857 (misses the specific mandatory versus discretionary distinction), source coverage 0.667. Agentic achieves 1.00 on both. This is exactly the query a credit union board asks during a capital crisis. Basic RAG's 24-point deficit is a 24-point operational risk.
Where Basic RAG Wins: Two Cases Worth Studying
Q3 (Basic wins by 9.0 points) is the SAR trigger and deadline question. Both pipelines achieve accuracy 1.00. The gap is entirely in source coverage: Basic RAG scores 1.00, Agentic RAG scores 0.50.
Why? Agentic retrieved two source files on the first pass: the main BSA reporting document plus a neighboring BSA procedures document that appeared semantically similar. The grader accepted this coverage (0 retries). But the generator only needed to cite one of the two files. Source coverage formula: cited docs / (cited docs ∪ final-pass docs) = 1 / 2 = 0.50.
This is the over-retrieval penalty. The agentic system, designed to be thorough, fetched a neighboring cluster that wasn't needed and paid for it in the coverage score. The lesson: a top_k=3 retrieval window that routinely pulls from adjacent clusters will systematically underperform on coverage metrics for simple queries. This is a tuning problem, not an architecture problem; tighter initial query rewriting or a lower retrieval temperature could mitigate it.
Q9 (Basic wins by 4.9 points, with 14× cost overrun) is the benchmark's most instructive failure. The HMDA/mortgage compliance query is a genuine corpus-gap scenario. The question asks about federal obligations "other than what NCUA covers," implicitly requiring HMDA (Regulation C), fair lending (ECOA, disparate impact), and potentially the Consumer Financial Protection Bureau's mortgage rules. The corpus has HMDA content but not the full regulatory cross-reference that this question implicitly demands.
The agentic system ran five retries across 99.7 seconds and consumed $0.178 in API costs, 14× more than Basic RAG's $0.013. At the end of five passes, the grader still hadn't reached its relevance threshold. The plateau detection should have caught this at retry 2–3. Looking at the grader score trajectory: the grader likely found partial HMDA coverage early but couldn't locate the CFPB/ECOA material, and the score plateau never triggered because the coverage kept marginally improving across passes.
The result: Basic RAG's straightforward answer, covering what it could find, scored 0.874. Agentic RAG's exhaustive but incomplete search scored 0.825, at 14× the cost and 10× the latency.
Q9 is not an argument against Agentic RAG. It is an argument for corpus completeness and plateau detection tuning.
Cost Analysis
Excluding Q9's outlier ($0.178), Agentic RAG averages $0.026 per query versus Basic RAG's $0.012, a 2.2× multiplier for 9 of 10 queries. Including Q9, the total session cost for 10 queries is Basic $0.119 vs Agentic $0.413.
For a compliance team running 200 queries per day:
- Basic RAG: ~$2.40/day ($720/year)
- Agentic RAG (no Q9-type queries): ~$5.20/day ($1,560/year)
- Agentic RAG (with occasional Q9-type corpus-gap queries): budget accordingly
The cost model scales with query complexity, not query volume, which is the correct property. Simple questions stay cheap. Hard questions cost more. Budget the retry multiplier against the cost of a missed regulatory obligation, not against the cost of a query.

Failure Analysis: Where Each Architecture Breaks Down
Where Basic RAG Succeeds
Basic RAG is genuinely strong on single-topic, well-phrased queries where the relevant content clusters around common vocabulary. Q1 (net worth ratios), Q5 (vendor management), and Q7 (IRR supervisory framework) all have this property. The relevant NCUA guidance is cohesive: PCA tables, vendor management principles, and NEV test thresholds each live in documents that use consistent vocabulary. A single retrieval pass at top-k=3 finds the right content.
Basic RAG also wins Q3 because the SAR question is direct: "what triggers a SAR, what is the deadline" and the BSA reporting document ranks unambiguously in the top-k. No retrieval gap, no vocabulary problem.
The Honesty Paradox in Practice
The scoring methodology includes a deliberate fix for honesty inflation. Without it, Basic RAG's confident admission that it cannot find SAR or lending limit content (on the three-threshold adversarial query) scores as 100% faithful, because every claim it makes is verifiably grounded in the retrieved IRR documents.
This is philosophically correct but operationally dangerous. The hallucination checker prompt explicitly excludes hedging statements:
Claims that describe what the model cannot find in the retrieved documents — such as "I cannot find guidance on X" or "The documents do not address Y" — are retrieval-coverage statements, not regulatory facts. Do not include these as claims in the output.
Without this exclusion, Basic RAG's strategic retreats look like model confidence. With it, the faithfulness score only measures claims the model actually attempted, removing the scoring advantage of incomplete answers.
Where Agentic RAG Degrades
Vocabulary mismatch leading to plateau loops is the primary Agentic failure mode. On Q9, the grader kept finding partial coverage across five passes because the HMDA/CFPB content it needed wasn't in the corpus in the form the grader expected. Each pass found something new but not the complete answer, just enough to avoid a clean plateau signal.
Grader false positives are the second failure mode, documented in detail for the pre-fix run of Q11 (the three-threshold adversarial query, not in the final 10-query benchmark). On that query, the grader returned grading_score=1.00 after two passes even though the SAR cluster had not been retrieved. The generator then correctly admitted it couldn't find the SAR content, but the retrieval loop had already exited; a third pass would have found the SAR document. The fix (tighter grader prompting with JSON schema enforcement) reduced this, but grader false positives on multi-part queries remain a real risk at production scale.
Retrieval confidence inflation on zero-retry queries appears in Q3's 18.8-second latency. Zero retries, but 18.8 seconds. The agentic pipeline has overhead from the rewriter, grader, and router calls, even when the first pass succeeds. For queries where Basic RAG would succeed in under 8 seconds, the agentic baseline overhead is 10–20 seconds of agent calls before generation even starts. This overhead is fixed cost, not retry cost.
Evaluator Brittleness
Same-model self-judging (Claude evaluating Claude) is a known risk in LLM-as-judge architectures. Two mitigations reduce it here:
- Structured JSON output at temperature=0: the grader must produce
grading_result,grading_score, andfeedbackas a JSON object, not as free text. This forces explicit per-dimension reasoning rather than a holistic "yes/no" impression. - Grader-verified context for generation: when the grader confirms coverage before the generator runs, the generator is working from a verified context window, not a speculative one. This is why Q6's production run (after the grader score fix) shows 0 unsourced claims across 15 extracted claims; the generator stays within the boundaries of what the grader confirmed.
The brittleness risk that remains: the grader model and the generator model are the same model (Sonnet 4.6). A systematic blind spot in Sonnet's regulatory understanding will appear in both the grader's coverage assessment and the generator's claims. Cross-model judging (e.g., GPT-4o as the judge) would address this but adds latency, cost, and vendor dependency.
Production Lessons Learned
Seven findings from building and running this benchmark that would have taken weeks to learn on a production compliance system:
1. Retry governance is not optional
Without plateau detection, a corpus-gap query will exhaust your retry budget on every run. Q9's production run (5 retries, $0.178, no improvement past retry 2) is a billing surprise waiting to happen at scale. The plateau rule (consecutive_stable_retries >= 2 AND best_grader_score >= 0.50) catches this pattern. Tuning the 0.50 threshold is the most important hyperparameter in the agentic architecture. Too low and you exit on partial answers; too high and you burn budget on corpus gaps.
2. Vocabulary injection is the bridge across semantic distance
The kb_manifest.json pre-computes per-document indexes: regulatory topics, specific numeric thresholds, CFR citations, and key terms. When the grader says "missing: single-borrower lending limit and collateral exception," the rewriter queries the manifest, finds that the Part 723 commercial loan policy document contains "15 percent of net worth," "readily marketable collateral," and "§723.8," and injects those terms directly into the next retrieval query.
Without this injection, the rewriter is guessing vocabulary for a regulatory document it has never seen. With it, the retry is targeted: embedding similarity for the correct document cluster increases substantially on the next pass.
3. The step log is the compliance audit trail
Every node execution in the agentic pipeline appends to step_log in the shared AgentState. The final AgenticRAGResult.step_log contains a complete record of every rewriter reformulation, every retrieval pass and its results, and every grader assessment with score and feedback. In a production compliance system, this log is the difference between an auditable AI response and a black box.
For demo purposes, the step log drives the real-time agent playback in the Streamlit UI: [✓ REWRITER], [✗ GRADER] score=0.40 — missing BSA/SAR cluster, [✓ GRADER] score=1.00 — all dimensions covered, making the iterative process visible to non-technical stakeholders.
4. Three rewriter prompt variants handle distinct failure modes
A single rewriter prompt is not enough for production use:
- Initial pass: Semantically richer reformulation of the original query, adding regulatory context, CFR references, and domain vocabulary
- Retry with vocabulary injection: Incorporates corpus-native terms from
kb_manifest.jsontargeting the identified gap, used when the grader knows what's missing - Dead-end reset: Abandons the current vocabulary thread and re-approaches from a different regulatory angle, used when
consecutive_stable_retriesindicates the current approach is stuck
The vocabulary injection variant is the most valuable. The dead-end reset is a last-resort mechanism that rarely fires in practice; if the corpus doesn't have the answer, a vocabulary pivot won't find it.
5. The Haiku-to-Sonnet cost cliff is real
Development on Haiku 4.5 ($0.08/M input, $0.40/M output) costs 37× less than production on Sonnet 4.6 ($3.00/M input, $15.00/M output). Q9's $0.178 production run would cost $0.0048 on Haiku, meaning the budget problem would be invisible in development. Always test retry-heavy edge cases against production pricing before committing to a retry budget.
6. Chunk size at 512 characters creates a multi-part answer problem
At 512 characters (~128 tokens) with 100-token overlap, a multi-part regulatory clause that spans 1,000 characters gets split across two chunks with a 100-token overlap region. If a question requires both halves of that clause, a single retrieval pass may get one chunk and miss the context that completes it.
This was not a bottleneck in this benchmark: all 10 queries have their core answers in single chunks, but it is a known limitation for questions about complex regulatory tables (like PCA capital tier thresholds, which span several rows). Re-ingesting at 1,024+ characters is a pending improvement.
7. Deterministic evaluation requires temperature=0
Both the grader and the hallucination checker run at temperature=0. This makes benchmark results reproducible across runs on the same corpus and query set. A grader running at temperature=0.7 will give different scores on identical context on 10–15% of runs, introducing measurement noise that makes it impossible to attribute score changes to pipeline changes rather than evaluation variance.
When to Use Agentic RAG vs Basic RAG
Deployment Decision Table
| Use Case | Basic RAG | Agentic RAG | Rationale |
|---|---|---|---|
| Internal knowledge search | Strong | Overkill | Single-topic queries, latency matters |
| Banking compliance QA | Weak | Strong | Multi-cluster queries, completeness critical |
| Audit workflow documentation | Weak | Strong | Cross-reference requirements, traceability required |
| Regulatory FAQ bot | Strong | Overkill | Well-scoped questions, volume is high |
| SAR / PCA multi-threshold queries | Fails | Required | Two to three regulatory clusters per question |
| HMDA / fair lending examination prep | Risky | Strong | Multi-framework compliance question |
| Real-time customer-facing chat | Strong | Too slow | Latency constraint; 30–100s is unacceptable |
| Board reporting / regulatory briefings | Risky | Strong | Incomplete answers create governance risk |
Architecture Selection Framework
A query is a candidate for Agentic RAG if it satisfies any of these conditions:
- Spans multiple regulatory topics, meaning the complete answer requires content from ≥2 distinct regulatory frameworks (e.g., both BSA and commercial lending in the same question)
- Contains specific numeric thresholds where a missed threshold creates direct regulatory exposure (PCA tiers, SAR thresholds, lending limits)
- Will inform a compliance decision or regulatory response, specifically any answer that goes in front of an auditor, examiner, or board
- Is adversarially phrased, using vocabulary from one domain to ask about another (e.g., "in the context of our IRR examination, what BSA obligations apply")
Single-topic, well-scoped lookups are Basic RAG territory. The routing decision should be made at query ingestion, not after the fact.

Stack Recommendation by Maturity
Development / prototype:
Basic RAG + Haiku 4.5. Fast iteration, near-zero cost. Sufficient to validate corpus quality and query design before adding agentic complexity.
Staging / pre-production:
Agentic RAG + Haiku 4.5 + plateau detection enabled. Validates retry logic at 37× lower cost than production. Run your full adversarial query set here before promoting.
Production:
Agentic RAG + Sonnet 4.6 + retry budget ≤ 6 + plateau detection tuned to your corpus coverage rate. Monitor retry_count per query in production telemetry; a rising average is either a corpus gap signal or a grader calibration problem.
Cost Governance Model
At Sonnet 4.6 pricing, a well-tuned Agentic RAG system that resolves in 0–2 retries costs $0.019–0.027 per query. Budget the outliers (queries that hit 5–6 retries) as exceptional events to be caught by monitoring, not as the average case to be priced into the baseline.
A simple cost governance rule: alert if any single query exceeds MAX_RETRIES × base_cost × 1.5. At Sonnet pricing, that is approximately 6 × $0.025 × 1.5 = $0.225 per query. Q9's $0.178 would have triggered this alert.
Not sure which architecture fits your workload?
Schedule a Free Consultation →Conclusion
Agentic RAG is not universally better than Basic RAG. It is better at a specific problem: retrieving complete answers to questions whose required information is scattered across semantically disconnected document clusters. In banking compliance, that problem description matches a substantial fraction of the questions that actually matter.
Agentic RAG won 8 of 10 queries, with an average +9.8 composite score and two losses to Basic RAG (one a coverage penalty, one a corpus-gap disaster). This is a fair summary of what this architecture buys you in a regulated compliance context. The two losses are not embarrassments; they are correct signals from the evaluation framework about where the architecture's costs exceed its benefits.
The finding that matters most is not in the score table. It is in the Q4 and Q8 results: 29-point and 24-point score gaps on the queries that describe a credit union in or near a regulatory crisis. Those are not queries where a compliance team wants "approximately right." They are queries where an incomplete answer gets documented in an examination finding.
The evaluation framework, built on five-dimension quality scoring with the grader's completeness score as the accuracy signal for the agentic pipeline, proved to be as important as the pipeline itself. Automated quality scoring without a completeness dimension will systematically overrate Basic RAG on multi-part queries. The honesty paradox is real, measurable, and fixable.
Agentic RAG becomes the right choice as three factors increase: correctness requirements, compliance sensitivity, and retrieval ambiguity. When all three are high — as they are in banking compliance and audit workflows — the architecture's additional latency and cost are not overhead. They are the price of getting the answer right.
The benchmark code, corpus, and evaluation harness are available on GitHub. If your organisation is evaluating production-grade RAG systems for regulated compliance workflows, reach out directly or connect on LinkedIn; I'm available for architecture advisory, implementation discussions and implementation assistance.
FAQ
What is the difference between Basic RAG and Agentic RAG?
Basic RAG retrieves documents once and generates an answer in a single pass. Agentic RAG adds a relevance grader that explicitly verifies whether the retrieved context covers every dimension of the question; if coverage is incomplete, a query rewriter reformulates and retries. The loop exits on confirmed coverage, budget exhaustion, or plateau detection. Basic RAG is faster and cheaper; Agentic RAG is more complete on multi-part queries.
What is Agentic RAG?
Agentic RAG is a retrieval-augmented generation architecture that replaces single-shot retrieval with an iterative loop. Instead of one retrieval pass and one generation call, an agentic pipeline uses a relevance grader to assess whether the retrieved context sufficiently covers the question, and a query rewriter to reformulate and retry if it does not. The loop continues until the grader approves coverage, the retry budget is exhausted, or a score plateau is detected. This makes it significantly more capable on multi-part questions but more expensive and slower than single-shot pipelines.
What is LLM-as-a-Judge?
LLM-as-a-Judge is a technique that uses a language model to evaluate the quality of another language model's output. In this benchmark, it plays two roles: the relevance grader (which evaluates whether retrieved chunks cover all dimensions of the question before generation) and the hallucination checker (which extracts factual claims from the generated answer and judges each claim against the retrieved source chunks). Both run at temperature=0 and produce structured JSON output to minimise evaluation variance.
Why does one-shot RAG fail in compliance environments?
One-shot RAG retrieves the top-k semantically similar chunks to the query phrasing. When a compliance question spans multiple regulatory topics with distinct vocabulary, the initial query phrasing can only retrieve chunks from one or two of the required clusters; the others remain invisible to the retriever because their vocabulary doesn't appear in the query. The LLM then generates a confident, well-sourced answer from incomplete context. In compliance, this is the most dangerous failure mode: a fluent, authoritative answer that misses critical regulatory obligations.
Is Agentic RAG worth the additional latency and cost?
It depends on the query. For single-topic, well-scoped compliance lookups, Basic RAG at 7–10 seconds and $0.009–0.015 per query is the right choice. For multi-part queries spanning two or more regulatory domains, the kind of question a compliance officer asks before a board meeting or an examination, Agentic RAG's 15–30 second and $0.020–0.035 per query is appropriate. The outlier is corpus-gap queries (Q9 in this benchmark: 100 seconds, $0.178), which requires plateau detection tuning to prevent. Budget based on query complexity distribution, not average cost.
How much does Agentic RAG cost compared to Basic RAG?
For queries that resolve in 0–2 retries (9 of 10 in this benchmark), Agentic RAG costs $0.019–0.027 per query versus Basic RAG's $0.009–0.015, a 2.2× multiplier. At 200 queries per day, that is roughly $840/year additional cost. The outlier is corpus-gap queries like Q9, which cost $0.178, which is 14× more than Basic RAG's $0.013 for the same query. Per-query cost monitoring with a ceiling alert (suggested: $0.225) prevents budget surprises.
How does LangGraph improve RAG orchestration?
LangGraph provides a typed state graph where each agent node reads from and writes to a shared AgentState dictionary. This enables clean separation of concerns, with the rewriter, retriever, grader, router, and generator as independent modules that communicate only through the state, while LangGraph handles the routing logic, state accumulation (via Annotated fields with operator.add), and execution tracing. The step_log field accumulates across all node executions, giving a complete audit trail of every retrieval pass and grader decision for free.
What is the honesty paradox in RAG evaluation?
An automated quality scorer that measures faithfulness (fraction of claims supported by retrieved chunks) will give high scores to an answer that admits it cannot find information, because "I cannot find guidance on X" is technically true about the retrieved documents. A pipeline that answers one of three sub-questions correctly and declines the other two scores 1.00 faithfulness, higher than a pipeline that answers all three but cites one unnecessary source. The fix: exclude retrieval-coverage statements from claim extraction, and use grader-verified completeness (not post-hoc faithfulness) as the accuracy signal for iterative pipelines.
What embedding model was used and why?voyage-law-2 from Voyage AI, a legal and regulatory text-optimized embedding model. Standard embeddings (OpenAI text-embedding-3-large, etc.) treat "net worth ratio" as a finance term similar to balance sheet and equity ratios. In NCUA regulatory documents, "net worth ratio" has a specific technical definition under 12 CFR Part 702 that is distinct from general accounting usage. Domain-specific embeddings align the similarity space with regulatory semantics, improving retrieval precision on compliance vocabulary.
About the Author
Prasad Kopanati is a 3x Founder, ex-Samsung, and an AI systems architect specialising in LLM-based retrieval and compliance automation for financial services. This benchmark is part of a series comparing RAG architectures on real-world regulated workloads. Published at SpaxialIQ.
Questions, feedback, or architecture discussions??
Book a Free 30-Min Call →